Lasso Regression
Lasso Regression, short for Least Absolute Shrinkage and Selection Operator, is another powerful regularization technique used in linear modeling. Like Ridge Regression, Lasso introduces a penalty to the regression model to prevent overfitting and manage multi-collinearity. However, the key difference lies in the nature of the penalty applied.
In Lasso Regression, the penalty added to the objective function is based on the absolute values of the coefficients (known as the L1 norm), as opposed to the squared coefficients used in Ridge Regression (L2 norm). Furthermore, the Lasso Penalty imposes it's impact by forcing coefficients of variables that are small to zero, thereby eliminating insignificant features.
$$ $$
Because we have seen how to implement Ridge regression, we will now demonstrate implementation of Lasso Regression. We will skip some ideas already covered earlier in the note.
Implementation of Lasso Regression on Hitter's Dataset
library(ISLR2)
library(tidyverse, quietly = TRUE)
hitters <- as_tibble(Hitters) %>%
filter( !is.na(Salary) )
dim(hitters)Define the Lasso Regression Model
In this example, we first define the Lasso recipe, model and then define a workflow to implement the model
Lassa Recipe
This recipe simply defines the formular of our regression model.
lasso_recipe <-
recipe(formula = Salary ~ ., data = train_data) %>%
step_novel(all_nominal_predictors()) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors()) %>%
step_normalize(all_predictors())Lasso Model
Now we implement the Lasso model by setting the variable
lasso_spec <-
linear_reg(penalty = tune(), mixture = 1) %>% # mixture 1 for L1 - Lasso penalty
set_mode("regression") %>%
set_engine("glmnet")
lasso_spec
Lasso Regression Workflow
We can now complete the model into a workflow
lasso_workflow <- workflow() %>%
add_recipe(lasso_recipe) %>%
add_model(lasso_spec)
lasso_workflowIn the Ridge regression, we saw the implementation of a workflow for indiviual models without grid search. Here, we go directly to using grid search by generating different values of the penalty
penalty_grid <- grid_regular(penalty(range = c(-2, 2)), levels = 50)
penalty_gridtune_grid - Hyperparameter search
We can no perform a grid search on the different parameters of lambda for our Lasso Regression
using the
tune_res <- tune_grid(
lasso_workflow,
resamples = hitters_fold,
grid = penalty_grid)
library(ggthemr)
ggthemr('fresh')
autoplot(tune_res)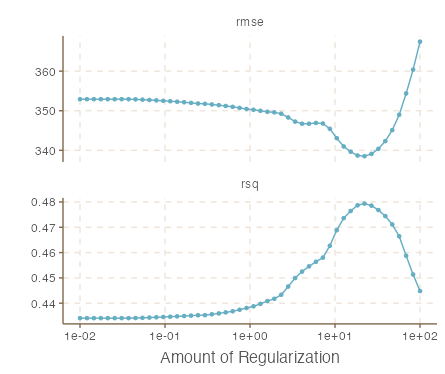
Select best performing parameter with select_best()
Again, we see mixed effects of the metrics with each lasso penalty. We can then extract the best model using the
best_penalty <- select_best( tune_res, metric = "rsq" )
lasso_final <- finalize_workflow(lasso_workflow, best_penalty)
lasso_final_fit <- fit(lasso_final, data = train_data)augment(lasso_final_fit, new_data = test_data) %>%
rsq(truth = Salary, estimate = .pred)